원인을 모르는 메모리 누수, 추측 대신 측정부터 시작했다
FE팀 회의에서 메모리 누수 얘기가 나왔다. nugu 몰 nextjs 인스턴스 메모리가 계속 차오르다 죽는 현상이 반복된다는 거였다. 다들 한마디씩 했지만, 정작 어디서 새는지 바로 알 수 없었다. 그래서 팀원 모두 한 번씩 들여다보기로 했다.
나는 누수가 진짜 있는지조차 확신이 없어 일단 재보기로 했다.
누수가 맞긴 한가
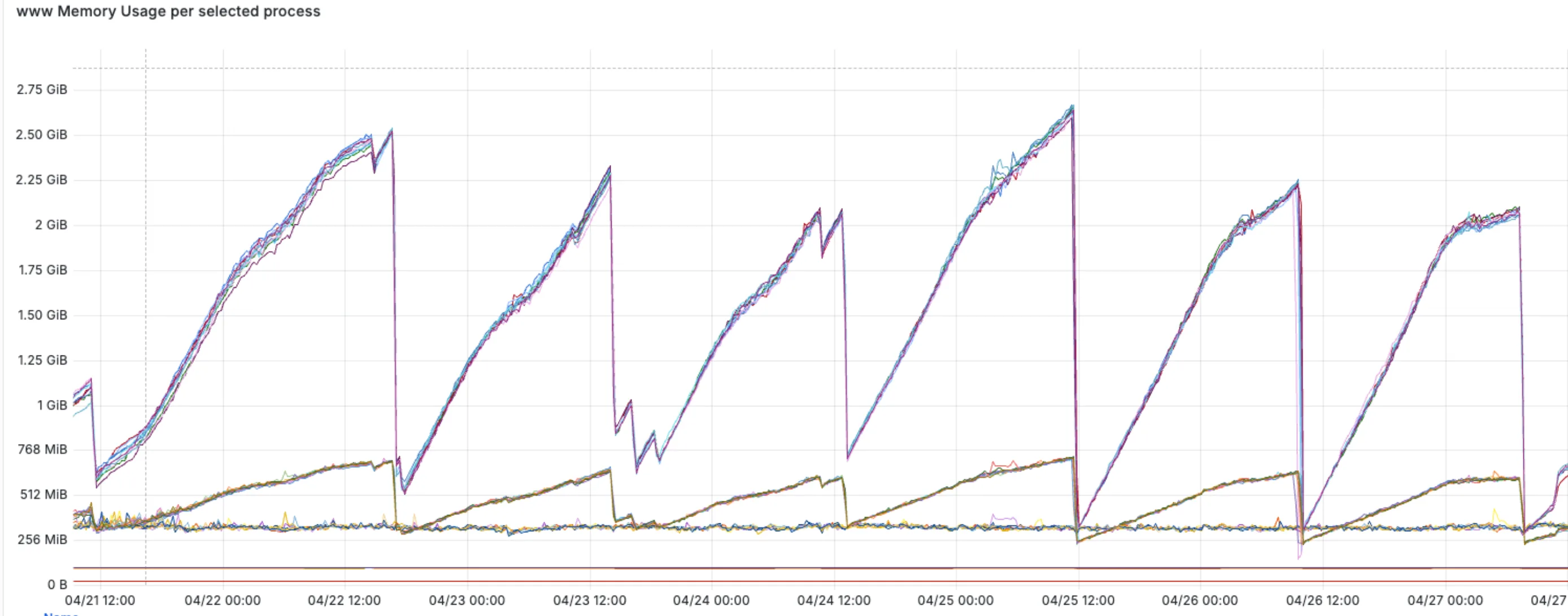
가장 먼저 한 일은 측정 수단을 만드는 거였다. 서버 프로세스의 메모리 상태를 그때그때 찍어주는 임시 내부 엔드포인트를 하나 붙였다. heapUsed, heapTotal, RSS 같은 숫자를 JSON으로 출력, 기록했다. 그리고 대충 60분 간격으로 호출해서 한 3번쯤 받아보니 그림이 분명해졌다.
| 시점 | GC 후 heapUsed |
|---|---|
| 5분 | 181 MB |
| 67분 | 264 MB |
| 136분 | 354 MB |
가비지 컬렉션이 한 번 돌고 난 뒤에도 바닥값이 계속 올라갔다. 분당 약 1.3 MB. 거의 완벽한 직선이었다.
"캐시가 정해진 크기까지 차오르는 자연스러운 현상"이란 가설을 바로 접었다. 자연스러운 캐싱이라면 어느 지점에서 평평해져야 한다. 130분 동안 평평해지는 구간이 없었다. 멈추지 않고 일정한 속도로 올라가기만 했다. 즉, 누수가 있었고 어딘가 한도 없이 쌓이고 있다는 뜻이었다.
멈추지 않고 들여다보기
운영 중인 서버를 분석해야 했다. 프로세스를 멈추거나 부하를 주면 안 됐다.
다행히 Node.js에는 프로세스를 죽이지 않고 디버거만 켜는 길이 있었다. kill이라는 이름 때문에 헷갈리지만, kill은 "프로세스를 죽인다"가 아니라 "프로세스에 시그널을 보낸다"는 뜻이고, 어떤 시그널을 보내느냐에 따라 동작이 완전히 달라진다.
| 시그널 | 번호 | 동작 |
|---|---|---|
SIGTERM | 15 | 종료 요청 (그냥 kill <pid> 하면 이게 가서 죽는다) |
SIGKILL | 9 | 강제 종료 (kill -9) |
SIGUSR1 | 10 | 사용자 정의 — Node.js는 이걸 받으면 inspector를 켠다 |
SIGUSR1은 OS가 의미를 정해두지 않은 "사용자 정의" 시그널이고, Node.js는 이걸 받으면 프로세스를 정상적으로 돌리면서 디버그 포트(9229)만 추가로 연다. 종료가 아니라 "디버거 켜라"는 신호인 셈이다.
Node.js 공식 문서도 이 동작을 명시한다 — Signal events: "
'SIGUSR1'is reserved by Node.js to start the debugger."
# 누수가 진행 중인 서버에서, V8이 도는 워커 프로세스 PID에 SIGUSR1 전송
sudo kill -USR1 <PID>
# inspector가 127.0.0.1:9229에만 listen하는지 확인 (외부 노출 X)
sudo ss -tlnp | grep 9229
# LISTEN ... 127.0.0.1:9229 ...포트가 localhost에만 열리니 외부에는 한 줄도 노출되지 않는다. 이 포트를 로컬까지 SSH 터널로 끌어왔다.
# 로컬 터미널에서: 로컬 9229 → 원격 127.0.0.1:9229
ssh -N -L 9229:127.0.0.1:9229 <서버 호스트>이제 로컬 크롬에서 chrome://inspect로 원격 프로세스에 붙어, 메모리 할당을 표본 추출(allocation sampling) 방식으로 추적했다. 모든 할당을 잡지 않고 일정 용량마다(기본 512KB) 한 번씩만 샘플링해서, 멈춤 없이 부하 1% 미만으로 돈다. 로드밸런서에 그대로 매달려 있어도 됐다.
운영 서버에 디버거를 붙이는 게 마음에 걸렸다. inspector를 끄는 표준 명령은 없지만 localhost에만 열려 있어 외부 영향이 없고, 분석이 끝나면 재시작으로 정리되는 선에서만 손댔다.
첫 결과는 ISR 캐시를 가리켰다. 짧은 주기로 다시 만들어지는 페이지 캐시가 메모리의 대부분을 차지하고 있었다. 동적 라우트가 많고 재생성 주기가 짧으면 캐시 항목이 폭증하니까 원인으로 그럴듯해 보였다.
하지만 표본 추출 한 장만으로는 "누수"인지 "캐시가 원래 크기까지 찬 것"인지 구분이 안 됐다.
힙 스냅샷 두 장
방법을 바꿨다. 힙 스냅샷을 시간 간격을 두고 두 번 떠서 비교하기로 했다. 스냅샷을 뜰 때마다 chrome inspector에서 먼저 GC를 강제로 돌려 일시적인 객체를 비웠다. 그래야 남아 있는 게 진짜 retain된 것이란 의미니까.
운영 트래픽에 영향을 덜 주려고, 디스크에 직접 힙 스냅샷을 쓰고 scp로 옮겼다. 60분 간격으로 두 장을 떠서 로컬로 가져와 비교 모드로 열었다.
여기서 구체적인 원인이 발견됐다. Freed(해제된 크기) 컬럼이었다.
| 객체 종류 | 증가 개수 | 해제 비율 |
|---|---|---|
| 일반 Object | +7,692 | 100% |
| 문자열 | +158,149 | 84% |
Query (TanStack Query) | +1,443 | 0% |
MutationObserver | +780 | 0% |
일반 객체와 문자열은 멀쩡히 해제되는데, TanStack Query의 내부 객체들만 해제 비율이 0이었다. 두 스냅샷 사이에 새로 생긴 Query 1,443개가 단 하나도 풀려나지 않았다.
ISR 캐시가 아니었다. 그 캐시에 유저 데이터가 많이 들어 있던 건 맞지만, 그 데이터를 붙잡고 놓지 않던 진짜 주체는 따로 있었다. 데이터 페칭 라이브러리인 TanStack Query였다.
누가 붙잡고 있나
확정하려면 retainer를 봐야 했다. 객체 하나를 찍으면 가비지 컬렉터의 뿌리(GC root)에서 그 객체까지 누가 붙잡고 있는지 역순으로 보여준다. 추적해 들어가니 경로가 이렇게 나왔다.
누수된 Query
← QueryCache (캐시 컨테이너 Map)
← 다른 Query가 같은 QueryCache를 참조
← removable.js의 gcTimeout 콜백 클로저
← Timeout 객체
← Node.js 활성 타이머 큐 ← GC ROOT
뿌리는 Node.js의 활성 타이머 큐였다. 그 타이머는 TanStack Query가 등록한 setTimeout이었고, 그 콜백이 Query 하나를 붙잡고, 그 Query가 QueryCache를 통해 같은 요청의 모든 Query를 줄줄이 붙잡고 있었다.
여기서 알게 된 중요한 사실 하나. 타이머 하나만 살아 있어도 그 QueryCache 전체가 산다. 모든 Query는 자기가 속한 QueryCache를 참조하고, 그 캐시는 다른 모든 Query를 들고 있기 때문이다. 그러니 긴 타이머를 가진 Query가 단 하나라도 있으면, 그 요청에서 만들어진 캐시 전체가 그 시간만큼 통째로 살아남는다.
양 끝은 안전하고, 중간이 위험했다
원인을 좁히니 TanStack Query의 gcTime이라는 설정으로 모였다. 캐시된 데이터를 언제 치울지 정하는 값이다. removable.js의 동작은 단순하다.
// @tanstack/query-core: removable.ts — scheduleGc (요약)
scheduleGc() {
if (isValidTimeout(this.gcTime)) { // Infinity면 false
this.#gcTimeout = setTimeout(() => this.optionalRemove(), this.gcTime)
}
}실제 코드:
removable.tsscheduleGc()(query-core 5.90.20). 실제로는setTimeout을timeoutManager로 한 번 감싸지만, 기본 구현은 그대로 전역setTimeout을 호출한다.
값에 따라 타이머가 어떻게 잡히는지 정리하면 이렇다.
| gcTime | setTimeout 등록 | 타이머 큐 점유 | 누수 위험 |
|---|---|---|---|
Infinity | 안 함 | 안 함 | 없음 |
| 24시간 같은 긴 값 | 함 | 그 시간 내내 | 큼 |
| 기본값(5분) | 함 | 5분 | 짧음 |
0 | 함 | 다음 틱에 즉시 발화 | 사실상 없음 |
흥미로운 건 양 끝(0과 Infinity)이 둘 다 안전하다는 점이다. Infinity는 아예 타이머를 안 만들고, 0은 만들자마자 다음 틱에 터져서 곧장 치워진다. 위험지대는 중간의 "유한하면서 긴" 값이다. 그 타이머가 타이머 큐를 오래 점유하면서, 자기가 속한 캐시 전체를 그 시간만큼 붙잡아 둔다.
문제의 코드는 24시간짜리 gcTime을 쓰는 훅에 있었다. 메인 페이지의 한 컴포넌트가 거의 안 바뀌는 설정 데이터를 하루 종일 캐시하려고 그렇게 설정해 뒀다. 브라우저(클라이언트)에서는 문제가 없었다. 문제는 그 컴포넌트가 서버 렌더링(SSR)에서도 그대로 실행된다는 거였다.
정리하면 특수했던 재료는 하나뿐이었다. 0도 Infinity도 아닌, 유한하면서 긴 gcTime. 나머지는 평범했다. SSR이라는 흔한 환경이면 충분했다.
그런데 한 가지가 걸렸다. fetch도 일어나지 않는 서버에서, useQuery는 대체 왜 이 타이머를 만드는 걸까?
"useQuery는 클라이언트에서만 동작한다"는 절반만 맞다
여기서 멘탈 모델을 고쳐야 했다. 나는 막연히 데이터 페칭 훅은 클라이언트에서만 동작한다고 알고 있었다. 정확히는 fetch가 클라이언트에서만 일어난다는 뜻이었지, 훅 호출 자체는 서버에서도 일어났다.
서버 렌더링 중에도 훅의 동기 부분은 그대로 실행됐다. 캐시 객체를 만들고 캐시에 등록하는 일이 이때 벌어진다. 그리고 그 등록 과정에서 Query 생성자가 scheduleGc()를 부르면서 setTimeout이 박힌다. fetch를 거는 비동기 부분만 useEffect 안에 있어서 서버에서 건너뛸 뿐이다.
// useQuery → useBaseQuery 내부 (요약)
function useQuery(options) {
const [observer] = useState(() => new QueryObserver(client, options))
// ↑ 서버에서도 실행 → QueryCache에 Query 등록 → setTimeout 박힘
useSyncExternalStore(observer.subscribe, ...) // ← subscribe는 서버에서 건너뜀
return observer.getCurrentResult() // ← 서버에서도 반환
}실제 코드:
useQuery는useBaseQuery.ts로 위임된다 (react-query 5.90.21). 위는 그중 서버 동작에 관여하는 부분만 추린 것이다.
즉 fetch가 일어나든 말든, Query는 서버에서 QueryCache에 등록되고 그 등록만으로 타이머가 생긴다. SSR은 요청마다 새 QueryClient를 만든다. 정상 동작이다. 하지만 그 타이머가 QueryClient를 붙잡으니, 응답 뒤 회수돼야 할 QueryClient들이 회수되지 못하고 요청 수만큼 쌓인다. 이게 누수의 본질이었다.
고치기
수정 자체는 한 줄짜리 분기였다. 서버에서는 gcTime을 0으로 두는 것.
gcTime: typeof window === 'undefined' ? 0 : 1000 * 60 * 60 * 24서버에서 0이면 setTimeout이 다음 틱에 즉시 터지고, 옵저버가 없으니 곧장 캐시에서 빠진다. SSR 응답 직후 캐시 전체가 GC 가능한 상태가 된다. 브라우저에서는 원래 의도대로 24시간을 유지한다. 확인된 누수원 두 곳에 같은 분기를 넣었다.
여기서 멈출 수도 있었지만 한 단계 위에도 안전망을 뒀다. 서버용 기본 옵션과 메인 QueryClient의 기본 gcTime을 서버에서 0으로 강제했다. 나중에 누군가 또 긴 gcTime을 박으면서 서버 분기를 빠뜨려도, 명시적으로 덮어쓰지 않는 한 자동으로 막히도록. 알게 된 핵심 원칙은 이거다. SSR에서는 응답보다 오래 사는 타이머를 만들지 않는다.
배포 후 같은 모니터링 스크립트로 다시 받아보니, 메모리가 일정 수준에서 평평해졌다. 분당 1.3 MB짜리 직선이 사라졌다.
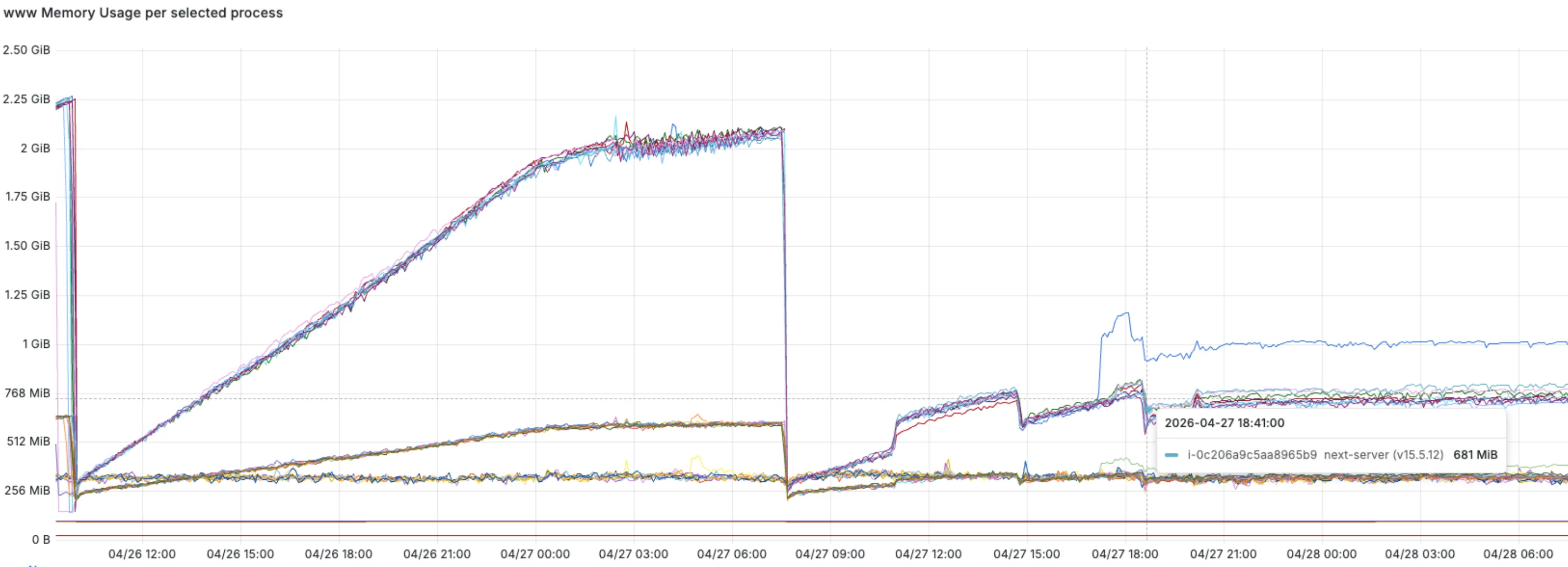
App Router였으면 안 났을까?
고치고 나서 '우리 Next.js 앱이 아직 Pages Router라서 난 건가?'란 생각이 들었다.
하지만 아니었다. 누수의 트리거는 라우팅 계층이 아니라 서버에서 useQuery의 동기 코드가 실행되는 순간이다. 그 순간 Query가 만들어지고 scheduleGc가 setTimeout을 박는다. App Router에서도 client 컴포넌트('use client')는 초기 HTML을 만들려고 서버에서 렌더링된다. 그 컴포넌트가 useQuery를 쓰면, 똑같이 서버에서 Query가 등록되고 타이머가 생긴다. QueryClient가 요청마다 새로 만들어지는 것도 두 라우터가 같다.
즉 문제의 그 훅들을 App Router로 그대로 옮겨놨어도 누수는 똑같이 재현되고, 고치는 분기도 동일하다. Next에 국한된 것도 아니었다. 같은 패턴이면 어느 SSR 환경에서든 날 수 있었다.
그래도 App Router로 전환했다면 쉽게 일어나지 않았을 것 같다. App Router의 권장 패칭은 RSC에서 바로 await fetch하는 거라, 그 경로엔 Query 객체가 안 만들어졌을 테니까. 하지만 server-render되는 client 컴포넌트가 긴 gcTime으로 useQuery를 단 하나만 써도 여전히 문제가 될 수 있다.
결국 라우터를 안 바꿔서 생긴 문제가 아니었다. 같은 원칙이 두 라우터 모두에 똑같이 적용된다.
남은 것
다른 팀원보다 비교적 빠르게 원인을 좁힐 수 있었던 건, 코드 읽기가 아니라 측정 수단을 먼저 만들었기 때문이다.
처음 의심했던 ISR 캐시는 틀린 가설이었다. 측정이 없었으면 그 그럴듯한 가설을 붙잡고 한참 헤맸을 거다. 힙 스냅샷의 해제 비율 0%라는 숫자 하나, retainer chain의 타이머 큐 하나가 추측을 뒤집었다.
측정 없이는 추측뿐이다. 그럴듯한 가설은 측정 앞에서 자주 틀린다. 다음에 또 원인 모를 누수를 만나면, 나는 또 재는 것부터 할 것 같다.
진단용으로 붙였던 엔드포인트와 스크립트는 검증이 끝난 뒤 정리했다.
참고
- TanStack Query — Server Rendering & Hydration — 서버 default
gcTime과 SSR에서의 캐시 수명을 다룬 공식 가이드. 이 누수의 핵심과 직결된다.
ISR 캐시를 범인으로 의심하던 시기에 조사한 자료들. 결과적으로 이번 누수의 원인은 아니었지만, Next.js 기본 in-memory 캐시가 사실상 unbounded로 동작한다는 별개의 이슈를 짚어준다.
- vercel/next.js #75314 — IncrementalCache의 in-memory LRU가 무한정 누적
- vercel/next.js #79588 — revalidate 사용 시 RAM 선형 증가
- vercel/next.js discussion #88078 — 기본 in-memory 캐시 핸들러가 사실상 unbounded라는 Vercel 팀 코멘트